O sistema linear¶
Seja um sistema linear conforme representado abaixo:
$$ \mathbf{A} \cdot \overrightarrow{x} = \overrightarrow{y} $$
Ou em sua forma aberta matricialmente:
$$ \left( \begin{matrix} a_{1,1} & a_{1,2} & ... & a_{1,m} \\ a_{2,1} & a_{2,2} & ... & a_{2,m} \\ ... & ... & ... & ... \\ a_{n,1} & a_{n,2} & ... & a_{n,m} \end{matrix} \right) \cdot \left( \begin{matrix} x_1 \\ x_2 \\ ... \\ x_m \end{matrix} \right) = \left( \begin{matrix} y_1 \\ y_2 \\ ... \\ y_n \end{matrix} \right) $$
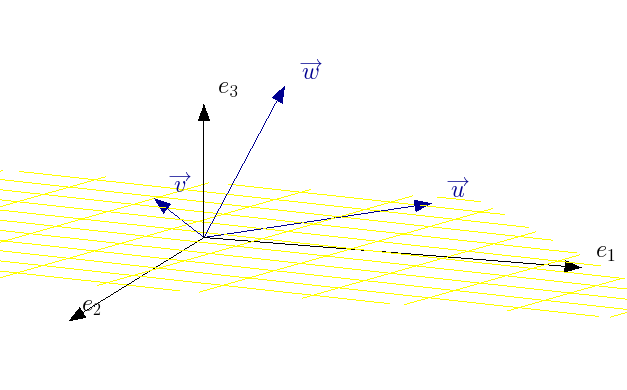
Onde o vetor $ \overrightarrow{y} $ pertence aos reais de dimensão $ n $, e o vetor $ \overrightarrow{x} $ pertence aos reais de dimensão $ m $. Cada vetor coluna da matriz $ \mathbf{A} $ pertence aos reais de dimensão $ n $, e cada vetor linha da matriz $ \mathbf{A} $ pertence aos reais de dimensão $ m $.
$$ \overrightarrow{y} \in \mathcal{R}^n $$$$ \overrightarrow{a}^C_j \in \mathcal{R}^n \ , \ \forall \ j =1..m $$$$ \overrightarrow{x} \in \mathcal{R}^m $$$$ \overrightarrow{a}^L_i \in \mathcal{R}^m \ , \ \forall \ i =1..n $$
Contudo, não necessariamente o vetor $ \overrightarrow{y} $ pode assumir qualquer vetor no espaço $ \mathcal{R}^n $, pois isto depende do posto da matriz $ \mathbf{A} $. Para entender, podemos re-escrever o sistema linear como:
$$ \underbrace{ \left( \begin{matrix} a_{1,1} \\ a_{2,1} \\ ... \\ a_{n,1} \end{matrix} \right) }_{ \overrightarrow{a}_1^C } \cdot x_1 + \underbrace{ \left( \begin{matrix} a_{1,2} \\ a_{2,2} \\ ... \\ a_{n,2} \end{matrix} \right) }_{ \overrightarrow{a}_2^C } \cdot x_2 + ... + \underbrace{ \left( \begin{matrix} a_{1,m} \\ a_{2,m} \\ ... \\ a_{n,m} \end{matrix} \right) }_{ \overrightarrow{a}_m^C } \cdot x_m = \underbrace{ \left( \begin{matrix} y_1 \\ y_2 \\ ... \\ y_n \end{matrix} \right) }_{ \overrightarrow{y} } $$
Ou seja:
$$ \overrightarrow{a}_1^C \cdot x_1 + \overrightarrow{a}_2^C \cdot x_2 + ... + \overrightarrow{a}_m^C \cdot x_m = \overrightarrow{y} $$
Logo, da expressão acima, fica evidente que o vetor $ \overrightarrow{y} $ é combinação linear dos vetores coluna da matriz $ \mathbf{A} $. Ou seja, $ \overrightarrow{y} $ pertence ao espaço vetorial dos vetores coluna da matriz $ \mathbf{A} $:
$$\overrightarrow{y} \ \in \ span \left(\overrightarrow{a}_1^C ,\overrightarrow{a}_2^C, ..., \overrightarrow{a}_m^C \right) $$
Se os vetores coluna apresentarem alguma dependência linear e a dimensão do espaço vetorial $ \mathcal{U} $ será menor que $ m $, e sempre igual ao posto da matriz $ \mathbf{A} $. Ou seja, se o posto da matriz $ \mathbf{A} $ for igual a $ p $, $ \overrightarrow{y} $ estará restrito a um espaço vetorial $ \mathcal{R}^p $.
Na transformação linear $ \mathbf{A} \cdot \overrightarrow{x} = \overrightarrow{y} $, podemos entender que:
- o vetor $ \overrightarrow{x} $ pode ser qualquer vetor em um espaço $ \mathcal{R}^m $;
- contudo, o vetor $ \overrightarrow{y} $ está restrito a um espaço $ \mathcal{R}^p $, onde $ p $ é o posto da matriz $ \overrightarrow{A} $
Em termos matemáticos, pode-se escrever:
$$ T_\mathbf{A} : \ \ \overrightarrow{x} \rightarrow \overrightarrow{y} $$$$ T_\mathbf{A} : \ \ \mathcal{R}^m \rightarrow \mathcal{R}^n $$
Contudo, $ \mathcal{R}^n $ é apenas o contradomínio da transformação. A imagem da transformação, onde $ \overrightarrow{y} $ verdadeiramente estará contido pode ser "menor" do que $ \mathcal{R}^n $, e é obrigatoriamente igual a $ \mathcal{R}^p $, em que $ p $ é o posto da matriz $ \mathbf{A} $.
$$ Im \left( T_\mathbf{A} \right) = \mathcal{R}^p, \ p = \rm{posto \ da \ matriz } $$
Mas e o espaço vetorial definido pelos vetores linhas da matriz $ \mathbf{A} $? Bem, um teorema do cálculo estabelece que:
$$ \rm{nº \ de \ colunas \ LI \ da \ matriz} \ \mathbf{A} = \rm{nº \ de \ linhas \ LI \ da \ matriz} \ \mathbf{A} = \rm{posto \ da \ matriz} \ \mathbf{A} = p $$
Ou seja, a dimensão do espaço vetorial coluna é a mesma dimensão do espaço vetorial linha. Vamos definir:
espaço vetorial coluna da matriz $ \mathbf{A} $ como $ \mathcal{U} $espaço vetorial linhada matriz $ \mathbf{A} $ como $ \mathcal{V} $
Então:
$$ dim \left( \mathcal{U} \right) = dim \left( \mathcal{V} \right) = p $$
Ou seja, ambos $ \mathcal{U} $, $ \mathcal{V} $ definem um $ \mathcal{R}^p $, não necessariamente o mesmo. Sabemos que são espaços de mesma dimensão são isomórficos; então os espaços vetoriais $ \mathcal{U} $, $ \mathcal{V} $ são isomórficos entre si. Isto signfica que um vetor $ \overrightarrow{x} $ que pertença a $ \mathcal{V} $ terá uma equivalência biunívoca com um vetor $ \overrightarrow{y} $ que pertença a $ \mathcal{U} $.
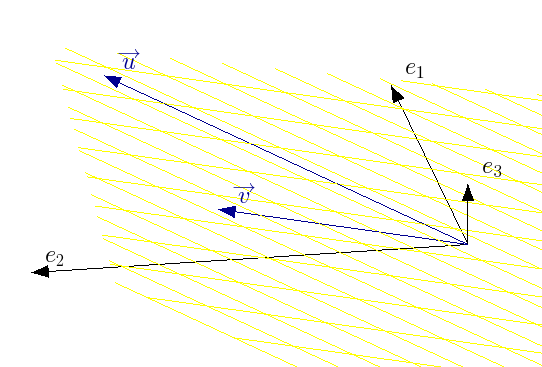
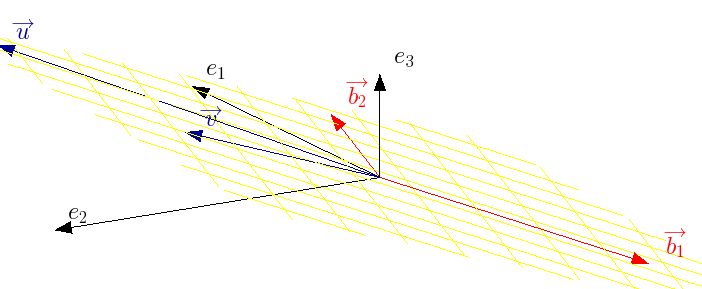
Para visualizar melhor, é conveniente observar bases ortogonais para os espaços linha e coluna, conforme segue.
Espaço vetorial coluna (pela decomposição svd)
Considere por exemplo, que escrevermos:
$$ \overrightarrow{y} = \mathbf{A} \cdot \overrightarrow{x} $$
Tomando a decomposição e sua parte vetorial, temos:
$$ \overrightarrow{y} = \mathbf{U_{\alpha}} \cdot \mathbf{S_{\alpha}} \cdot \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x} $$$$ \overrightarrow{y} = \mathbf{U_{\alpha}} \cdot \mathbf{S_{\alpha}} \cdot \underbrace{ \left( \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x} \right) }_{\overrightarrow{z}} $$$$ \overrightarrow{y} = \mathbf{U_{\alpha}}\cdot \cdot \mathbf{S_{\alpha}} \cdot \overrightarrow{z} $$$$ \overrightarrow{y} = \begin{pmatrix} | & | & | & | \\ \overrightarrow{u_{\alpha,1}} & \overrightarrow{u_{\alpha,2}} & \overrightarrow{u_{\alpha,3}} & \overrightarrow{u_{\alpha,4}} \\ | & | & | & | \end{pmatrix} \cdot \begin{pmatrix} \sigma_1 & 0 & 0 & 0 \cr 0 & \sigma_2 & 0 & 0 \cr 0 & 0 & \sigma_3 & 0 \cr 0 & 0 & 0 & \sigma_4 \end{pmatrix} \cdot \begin{pmatrix} z_1 \\ z_2 \\z_3 \\z_4 \end{pmatrix} $$$$ \overrightarrow{y} = z_1 \cdot \sigma_1 \cdot \begin{pmatrix} | \\ \overrightarrow{u_{\alpha,1}} \\ | \end{pmatrix} + z_2 \cdot \sigma_2 \cdot \begin{pmatrix} | \\ \overrightarrow{u_{\alpha,2}} \\ | \end{pmatrix} + z_3 \cdot \sigma_3 \cdot \begin{pmatrix} | \\ \overrightarrow{u_{\alpha,3}} \\ | \end{pmatrix} + z_4 \cdot \sigma_4 \cdot \begin{pmatrix} | \\ \overrightarrow{u_{\alpha,4}} \\ | \end{pmatrix} $$
Ou seja, o vetor $ \overrightarrow{y} $ pertence ao espaço vetorial dos vetores coluna de $ \mathbf{U_{\alpha}} $. Tudo bem, nada de novo, havíamos dito que a matriz $ \mathbf{U_{\alpha}} $ gera, em seus vetores coluna, o mesmo espaço vetorial gerado pelos vetores coluna da matriz $ \mathbf{A} $.
Os $ \sigma$ 's são ordenados tipicamente do maior para o menor: $ \sigma_1 > \sigma_2 > \sigma_3 > \sigma_4 $. Os $ \overrightarrow{u_{\alpha}} $'s são unitários. Assim, a direção que tipicamente mais "impacta" o vetor $ \overrightarrow{y} $ tende a ser a direção 1, seguida da direção 2, direção 3 e por fim a direção 4. Se o $ \sigma $ associado a uma direção for muito pequeno comparado aos demais, pode-se pensar que desprezar esta direção gera pouco impacto no vetor $\overrightarrow{y} $. De fato, isto fundamenta uma análise de grande importância na estatística: a análise dos componentes principais. Veremos a aplicação desta análise mais à frente na disciplina; por hora vamos nos contentar em entender que as direções $ \overrightarrow{u_{\alpha,}}'s $ representam as direções ortogonais que contém a informação do espaço vetorial coluna da matriz $ \mathbf{A} $.
Espaço vetorial linha (pela decomposição svd)
Na verdade, podemos observar isto pela decomposição em valores e vetores singulares da matriz $ \mathbf{A} $, considerando que vamos recuperar os $ \overrightarrow{x} $ que estão associados a transformação linear. Vamos designar por $ \overrightarrow{x}_{\alpha} $, porque como será mostrado, está associado ao espaço vetorial $ \mathcal{V} $. Então
$$ \mathbf{A} \cdot \overrightarrow{x}_{\alpha} = \overrightarrow{y} $$$$ \mathbf{U_{\alpha}} \cdot \mathbf{\Sigma_{\alpha}} \cdot \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x}_{\alpha} = \overrightarrow{y} $$$$ \overrightarrow{x}_{\alpha} = \mathbf{V_{\alpha}} \cdot \mathbf{\Sigma_{\alpha}}^{-1} \cdot \mathbf{U_{\alpha}}^T \cdot \overrightarrow{y} $$
Chamando $ \overrightarrow{z} = \mathbf{U_{\alpha}}^T \cdot \overrightarrow{y} $, temos:
$$ \overrightarrow{x}_{\alpha} = \mathbf{V_{\alpha}} \cdot \mathbf{\Sigma_{\alpha}}^{-1} \overrightarrow{z} $$$$ \overrightarrow{x}_{\alpha} = \frac{z_1}{\sigma_1} \cdot \overrightarrow{v_1}_{\alpha} \cdot \frac{z_2}{\sigma_2} \cdot \overrightarrow{v_2}_{\alpha} + ... $$
Note que, se queremos obter $ \overrightarrow{x}_{\alpha} $ a partir de $ \overrightarrow{y} $, então pela equação acima, $ \overrightarrow{x}_{\alpha} \in span \left( \overrightarrow{v_1}_{\alpha}, \overrightarrow{v_2}_{\alpha}, ... \right) $, ou seja, $ \overrightarrow{x} \in \mathcal{V} $.
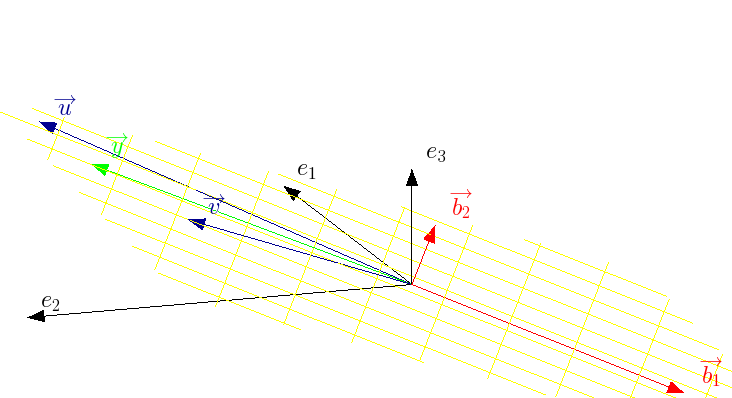
Entendendo as infinitas soluções
Vimos que qualquer vetor $ \overrightarrow{x}_{\alpha} $ pertencendo ao espaço vetorial linha da matriz $ \mathbf{A} $ tem uma relação biunívoca com um vetor $ \overrightarrow{y} $ que obrigatoriamente está no espaço vetorial coluna da matriz $ \mathbf{A} $. Contudo, algo realmente interessante surge quando observamos o espaço nulo linha da matriz $\mathbf{A} $, isto é, $ kernel \left( \mathcal{V} \right) $. Note que vetores que pertencem ao espaço nulo linha são ortogonais aos vetores linha da matriz $ \mathbf{A} $. Com isto, seja $ \overrightarrow{x}_{\beta} \in kernel \left( \mathcal{V} \right) $. Então:
$$ \mathbf{A} \cdot \overrightarrow{x}_{\beta} = \begin{pmatrix} - & \overrightarrow{a^L_1} & - \\ - & \overrightarrow{a^L_2} & - \\ - & ... & - \\ - & \overrightarrow{a^L_{n-1}} & - \\ - & \overrightarrow{a^L_n} & - \end{pmatrix} \cdot \overrightarrow{x}_{\beta} = \begin{pmatrix} \left< \overrightarrow{a^L_1}, \overrightarrow{x}_{\beta} \right> \\ \left< \overrightarrow{a^L_2}, \overrightarrow{x}_{\beta} \right> \\ ... \\ \left< \overrightarrow{a^L_{n-1}}, \overrightarrow{x}_{\beta} \right> \\ \left< \overrightarrow{a^L_n}, \overrightarrow{x}_{\beta} \right> \end{pmatrix} = \begin{pmatrix} 0 \cr 0 \cr ... \cr 0 \cr 0 \end{pmatrix} $$
Ou seja:
$$ \mathbf{A} \cdot \overrightarrow{x}_{\beta} = \overrightarrow{0}, \ \ \rm{se} \ \ \overrightarrow{x}_{\beta} \in \ kernel \left( \mathcal{V} \right) $$
Com isto, considere um problema com infinitas soluções, e com a solução $ \overrightarrow{x}_{\alpha} $
$$ \mathbf{A} \cdot \overrightarrow{x}_{\alpha} = \overrightarrow{y} $$
Tomando a relação anterior, para $ \overrightarrow{x}_{\beta} \in \ kernel \left( \mathcal{V} \right) $, temos:
$$ \mathbf{A} \cdot \overrightarrow{x}_{\alpha} = \overrightarrow{y} $$$$ \mathbf{A} \cdot \overrightarrow{x}_{\beta} = \overrightarrow{0} $$
Que somando leva a:
$$ \mathbf{A} \cdot \left( \overrightarrow{x}_{\alpha} + \overrightarrow{x}_{\beta} \right) = \overrightarrow{y} $$
Ou seja, $ \overrightarrow{x}_{\alpha} + \overrightarrow{x}_{\beta} $ também é solução do problema.
Podemos então entender qualquer solução particular $ \overrightarrow{x^*} $ em sua componente no espaço vetorial de $ \mathbf{V_{\alpha}} $ e no espaço nulo $ \mathbf{V_{\beta}} $.
Quando decompomos $ \mathbf{A} $ na decomposição svd, temos:
$$ \mathbf{A} \cdot \overrightarrow{x} = \overrightarrow{y} $$$$ \mathbf{U_{\alpha}} \cdot \mathbf{S_{\alpha}} \cdot \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x} = \overrightarrow{y} $$
Ao multiplicar por $ \mathbf{U_{\alpha}}^T $, temos:
$$ \mathbf{U_{\alpha}}^T \cdot \mathbf{U_{\alpha}} \cdot \mathbf{S_{\alpha}} \cdot \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x} = \mathbf{U_{\alpha}}^T \cdot \overrightarrow{y} $$
Ao multiplicar por $ \mathbf{S_{\alpha}}^{-1} $, temos:
$$ \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x} = \mathbf{S_{\alpha}}^{-1} \cdot\mathbf{U_{\alpha}}^T \cdot \overrightarrow{y} $$
Por fim, ao multiplicar por $ \mathbf{V_{\alpha}} $, teremos obrigatoriamente o resultado projetado sobre o plano do espaço vetorial $ \mathcal{V} $.
$$ \underbrace{ \mathbf{V_{\alpha}} \cdot \mathbf{V_{\alpha}}^T \cdot \overrightarrow{x} }_{x_{\alpha}} = \mathbf{V_{\alpha}} \cdot \mathbf{S_{\alpha}}^{-1} \cdot\mathbf{U_{\alpha}}^T \cdot \overrightarrow{y} $$
O $ x_{\alpha} $ é a "parte fixa" da solução do problema. Podemos somar ao $ x_{\alpha} $ qualquer valor dentro do espaço nulo, que a solução permanece válida. Logo, a solução geral do problema linear fica:
$$ x = x_{\alpha} + \lambda_1 \cdot \overrightarrow{v}_1 + \lambda_2 \cdot \overrightarrow{v}_2 $$
, em que $ \overrightarrow{v}_1,\overrightarrow{v}_2 \in \ kernel \ \mathcal{V} $
Claramente, ao tomar um vetor no espaço nulo, sendo este ortogonal ao espaço vetorial $ \mathcal{V} $, estaremos apenas aumentando sua normal. Logo, o vetor solução de menor norma possível é o $ x_{\alpha} $.